La génèse
La vérification des systèmes ferroviaires couvre de nombreux aspects et nécessite un grand nombre de vérifications croisées, effectuées par un large éventail d’acteurs, notamment le concepteur du système, l’entreprise chargée de son exploitation, l’organisme de certification, etc. Même si une automatisation complète n’est pas possible, toute vérification automatique est la bienvenue car elle contribue à améliorer le niveau de confiance général.
En effet, un système ferroviaire est un ensemble de spécifications de sous-systèmes très dépendants et ces dépendances doivent être vérifiées. Elles peuvent être basées sur les règles de signalisation ferroviaire (qui sont spécifiques à chaque pays ou même à chaque entreprise d’un même pays), sur les caractéristiques du matériel roulant (taille ou configuration constante ou variable du train) et sur les conditions d’exploitation.
En France, le laboratoire AQL RATP a initié le développement d’un outil générique de vérification des données de bord de voie pour la ligne 1 du métro de Paris qui est en cours d’automatisation. Cet outil, basé sur l’évaluateur de prédicats PredicateB, est capable d’analyser des données (formats XML, csv ou texte), de charger des règles et de vérifier que les données sont conformes aux règles. Testé initialement sur les données de configuration de la ligne 13, l’outil a permis de vérifier 400 définitions et 125 règles en 5 minutes.
Dans le cadre du projet DEPLOY, l’université de Düsseldorf et Siemens Transportation Systems ont élaboré une nouvelle approche, basée sur le vérificateur de modèles ProB, qui permet de réduire considérablement la durée de la validation, qui passe de six mois à quelques minutes. Les données sont extraites du code source ADA et les propriétés proviennent des modèles B. Dans le cas du projet San Juan, 79 fichiers avec un total de 23 000 lignes de B sont analysés pour extraire 226 propriétés et 147 assertions. La vérification a duré 1017 secondes et a conduit à la découverte de 4 fausses formules. ProB a ensuite été expérimenté avec grand succès sur plusieurs projets : Navette aéroport Roissy Charles de Gaule, ligne 9 de Barcelone, ligne 4 de San Paulo, ligne 1 de Paris et ligne 1 d’Alger. A cette occasion, ProB a été légèrement amélioré afin de pouvoir traiter des problèmes à grande échelle et bien validé afin de faciliter son acceptation par un organisme de certification. Cependant, l’analyse des fausses propriétés reste difficile.
Data Table Validation Tool
Alstom Transport Information Solutions a décidé d’expérimenter une nouvelle approche en réutilisant les caractéristiques réussies des expériences précédentes.
Un nouvel outil, DTVT, est défini et mis en œuvre. Sa structure est présentée ci-dessous.
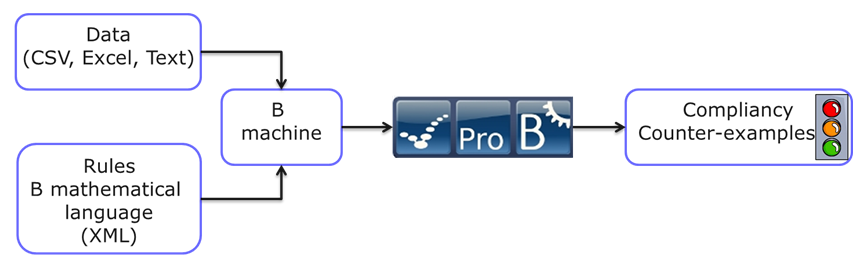
Les données d’entrée sont au format csv. Les éléments de données sont identifiés par leur fichier conteneur et leur nom.
Les types de base pris en charge sont INT, BOOL et STRING. Les éléments de données sont des séquences de ces types de base. Les valeurs sont extraites de fichiers xls.
Les règles de vérification sont exprimées à l’aide du langage mathématique B et structurées comme des opérations B. Au lieu de devoir traiter des prédicats quantifiés trop volumineux, une règle de vérification est décomposée en petites étapes qui permettent d’afficher un message d’erreur précis aidant à déterminer la source de l’erreur. Une règle est composée d’un ou plusieurs contre-exemples. Les exemples de comptage sont évalués dans l’ordre où ils sont définis. Le mot-clé COUNTEREXAMPLE est suivi d’un message formaté (%1, %2, %3, etc. représentent la valeur du premier, deuxième, troisième paramètre de la substitution ANY suivante). La substitution ANY permet de filtrer des données ou de calculer des valeurs. La substitution ANY est suivie d’un champ EXPECTED. Si certaines valeurs des paramètres de la substitution ANY satisfont le prédicat de cette substitution mais ne satisfont pas le prédicat du champ EXPECTED, le message d’erreur est affiché avec ses paramètres instanciés.
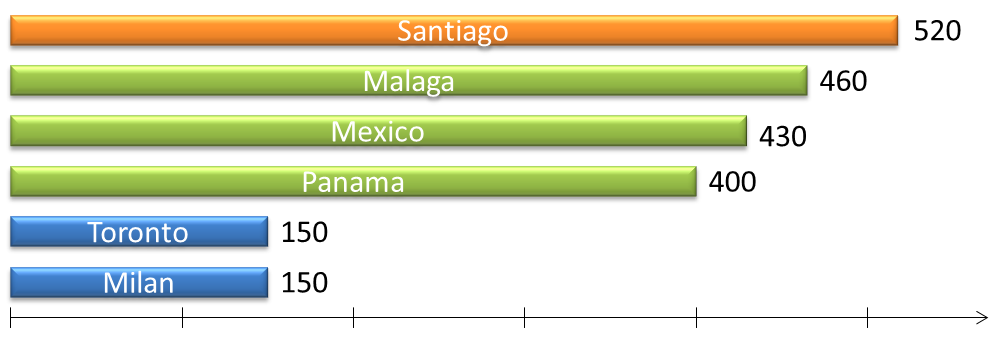
ProB est l’outil central de la vérification. Il a été modifié afin de produire un fichier contenant tous les contre-exemples détectés (voir figure 5) et légèrement amélioré pour mieux prendre en charge certains mots-clés B. Le DTVT a été expérimenté avec succès dans le cadre de plusieurs développements en cours (Mexique, Toronto, Sao Paulo et Panama) pour vérifier jusqu’à 100 000 cellules Excel par rapport à 500 règles. Une première phase a permis de définir les concepts requis, les constructions intermédiaires (prédicats utilisés par plusieurs règles) et de formaliser un ensemble de règles génériques partagées par tous les projets. Au cours des cycles suivants, des règles et des fichiers de données spécifiques aux projets ont été ajoutés. Une vérification complète est effectuée en 10 minutes environ, y compris le rapport de vérification. Le processus est entièrement automatique et peut être rejoué sans aucune intervention humaine lorsque les valeurs des données sont modifiées.
Références
- Leuschel, Michael and Falampin, Jérôme and Fabian, Fritz and Daniel, Plagge (2009), Automated Property Verification for Large Scale B Models. In: Proceedings FM 2009. Springer-Verlag.
- Michael Leuschel (2012), Formal Mind, ProB, ProR and Data Validation with B, FM’2012, Industray Day.
- Thierry Lecomte, Lilian Burdy, Michael Leuschel (2012), Formally Checking Large Data Sets in the Railways. In Proceedings of DS-Event-B 2012: Workshop on the experience of and advances in developing dependable systems in Event-B, in conjunction with ICFEM 2012 – Kyoto, Japan, November 13, 2012